软件与系统安全课程复习
实验班分值: 期末考试: 50% 上机作业(2次): 15%×2 平时书面作业(1次): 10% 线上学习成绩: 10%
题型: 客观题(10分=2*5多选)+主观题(90分=简答【不要太少字,解释一些概念都好】)
※ 文章标记:重点 次重点 (优先看重点,看完再看次重点,其他的基本不用看)※
复习重点
1.概述
2.技术基础
威胁模型, 可信计算基(Trusted computing base), 安全策略与策略执行, 通用的安全设计原则, 攻击面
x86概念与内存模型, 寄存器与数据类型,指令集(栈操作和函数调用相关)与调用惯例, 静态反汇编, ELF文件格式
2.1 信任
- 主体被起到表现出某种行为的程度
- 可信计算基TCB
- 可信根TPM/TCM
- P: Platform
- 可信平台模块,植于计算机内部为计算机提供可信根的芯片。该芯片的规格由可信计算组(Trusted Computing Group)来制定
- C: Cryptography
- 可信密码模块; 是可信计算平台的硬件模块,为可信计算平台提供密码运算功能,具有受保护的存储空间,是我国国内研究,与TPM对应
- P: Platform
2.2 威胁模型
- 什么可信什么不可信 攻击者的资源动机能力 攻击造成的影响
- 威胁模型例子:
- 接收客户端请求的web服务器
- 什么可信: web服务器
- 什么不可信: 客户端
- 客户端可能发送恶意输入
- 客户端可能发起拒绝服务攻击
- 客户端可能接管web服务器: 偷取敏感信息; 实际上是一个“软件可信但输入不可信”的场景
- 保护计算机系统免受恶意代码和恶意输入的威胁 系统本身是可信的
- 保护软件免受恶意篡改 代码本身是可信的 但代码运行在一个不可信的系统上
- 接收客户端请求的web服务器
- 漏洞
- 可以被对缺陷具有利用能力的攻击者访问并 利用的缺陷
- 要素(对应上CIA三要素)
- 缺陷 (flaw) - 机密
- 攻击者能访问缺陷 - 完整(权限管理)
- 攻击者有利用缺陷的能力 - 可用
2.3 安全策略和策略执行
安全策略
- 谁被允许做什么
- CIA模型
- 机密性(Confidentiality)
- 信息仅能被授权者知道 例: Bob买了1000股微软股票且希望此信息保密
- 完整性(Integrity)
- 系统中存储的信息是正确(未被篡改的), 攻击者无法修改被保护 的信息 例: Bill Gates卖了100万股微软股票; 此信息是公开的, 但没有 人能将100万改为1000万
- 可用性(Availability)
- 当需要信息或服务时, 信息或服务可用, 攻击者无法阻碍计算过程 例: Bob想从经纪人那里买1000股微软股票, 但经纪人不在 (生病了)
- 机密性(Confidentiality)
2.4 安全设计原则
- 开放设计(Open Design)原则
- 安全不能依赖于对设计和实现的保密(通过“晦涩”得到的安全)
- 最小权限(Least Privilege)原则
- 主体应仅被授予完成其任务所必需的权限
- 权限在需要时添加, 在使用后收回
- 缺省失败安全(Fail-Safe Defaults)原则
- 指定“合法”字符, 并丢弃所有非合法的字符; 而不是指定 “非法”字符且仅丢弃它们(“白名单”而非“黑名单”)
- 安全机制经济性(Economy of Mechanism)原则
- 每个工具完成单一任务
- 定义完备的接口
- 完全仲裁(Complete Mediation)原则
- 检查并授权对于对象的每一次访问
- 特权分离(Separation of Privilege)原则
- 责任分裂
- 填支票数额的人和签支票的人应为不同的人
- 责任分裂
- 最小通用机制(Least Common Mechanism)原则
- 访问不同资源的机制应不是共享的
- 心理可接受性(Psychological Acceptability)原则
- 安全机制不应增加访问资源的难度
2.5 攻击面
- 攻击者的可访问性质:能够被攻击者访问到的入口点
- 如何识别
- 识别出可能被攻击者控制的系统资源子集
- 谁是程序攻击者? 哪些资源可能被他们控制?
- 识别出这些系统资源在何时会被程序使用(即程序入口点)
- 程序访问外部源(如文件, 网络socket等)所使用的程序语句 是入口点
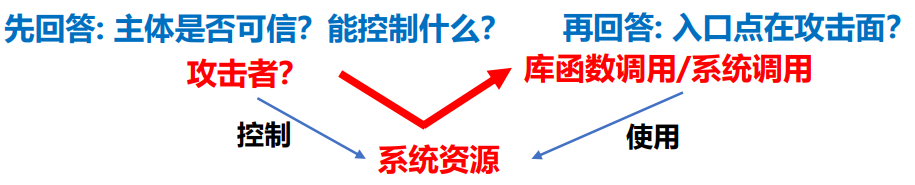
- 识别出可能被攻击者控制的系统资源子集
2.6 软件逆向基础
- X86小端序
- X86
- IA-32
- 内存模型:段地址;
- 逻辑地址=段选择器+偏移量
- IA-32
- x86-64
- X86
- 寄存器与数据类型
- x86通用寄存器8个32位的
- EAX:(操作数和结果数据的)累加器
- EBX:(在DataS段中数据的指针)基址寄存器
- ECX:(字符串和循环操作的)计数器
- EDX:(I/O指针)数据寄存器
- EDI: 变址寄存器, 字符串/内存操作的目的地址
- ESI: 变址寄存器, 字符串/内存操作的源地址
- EBP:(StackSeg段中的)栈内数据指针, 栈帧的基地址, 用于为函数调用创建栈帧
- ESP:(StackSeg段中的)栈指针, 栈区域的栈顶地址
- x86的32位特殊寄存器 —— 指令指针寄存器
- EIP: 存放当前代码段中将被执行的下一条指令的线性地址偏移
- 不能直接修改EIP, 修改途径:指令JMP, Jcc, CALL, RET
- 程序运行时, CPU根据CS段寄存器和EIP寄存器中的地址偏移读取下一条指令, 将指令传送到指令缓冲区, 并将EIP寄存器值自增, 增大的大小即被读取指令的字节数不能直接修改EIP, 修改途径:指令JMP, Jcc, CALL, RET中断或异常
- EIP: 存放当前代码段中将被执行的下一条指令的线性地址偏移
- x86通用寄存器8个32位的
2.7 内存模型^
- 分段内存模型:程序内存由一系列独立的地址空间(称为“段”)组成。代码、数据和栈在不同的段中。 逻辑地址=段选择器+偏移量
- 保护模式下的内存管理:分段(必须)+ 分页(可选)
- 物理地址是CPU访问的实际内存位置
- CPU的内存管理单元(MMU)透明地将虚拟地址(逻辑地址)转换为物理地址
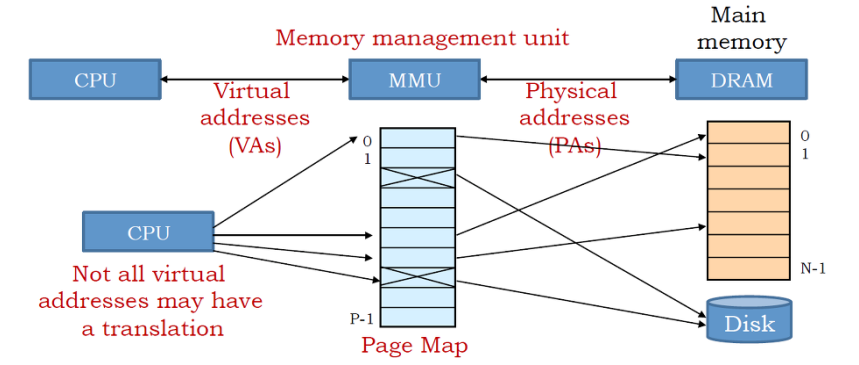
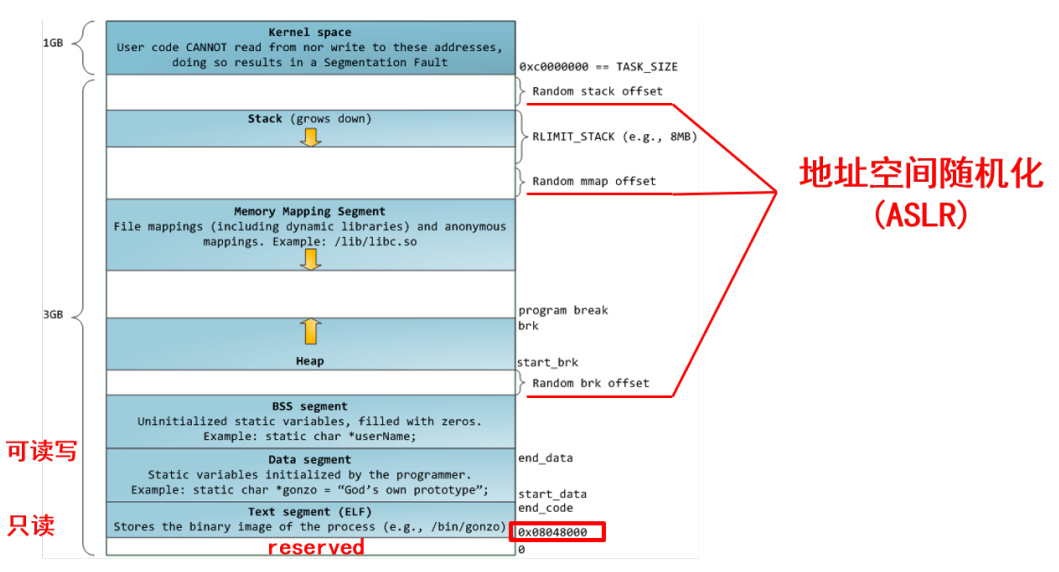
- 分层介绍
- BSS:Block Started by Symbol通常是指用来存放程序中未初始化的全局变量的一块内存区域。
- data:数据段(data segment)通常是指用来存放程序中已初始化的全局变量的一块内存区域。【静态局部变量在这】
- text段:代码段(code segment/text segment)通常是指用来存放程序执行代码的一块内存区域。这部分区域的大小在程序运行前就已经确定,并且内存区域通常属于只读(某些架构也允许代码段为可写,即允许修改程序)。
- 堆(heap):堆是用于存放进程运行中被动态分配的内存段,它的大小并不固定,可动态扩张或缩减。当进程调用malloc等函数分配内存时,新分配的内存就被动态添加到堆上(堆被扩张);当利用free等函数释放内存时,被释放的内存从堆中被剔除(堆被缩减)。
- 栈(stack):栈又称堆栈,是用户存放程序临时创建的局部变量,也就是说我们函数括弧“{}”中定义的变量(但不包括static声明的变量,static意味着在数据段中存放变量)。除此以外,在函数被调用时,其参数也会被压入发起调用的进程栈中,并且待到调用结束后,函数的返回值也会被存放回栈中。由于栈的先进先出(FIFO)特点,所以栈特别方便用来保存/恢复调用现场。从这个意义上讲,我们可以把堆栈看成一个寄存、交换临时数据的内存区。在代码段中,也有可能包含一些只读的常数变量,例如字符串常量等。
- text和data段都在可执行文件中(在嵌入式系统里一般是固化在镜像文件中),由系统从可执行文件中加载;而bss段不在可执行文件中,由系统初始化。
2.8 指令集^
特别是(栈操作和函数调用相关)与调用惯例
栈操作与函数调用指令
栈: 线性地址空间中连续的内存区域, 后进先出, 存在于一个栈段内, 该栈段可由段寄存器SS检索的段描述符指向。
- 任意时刻, ESP寄存器所包含的栈指针均指向栈顶位置
- 所有针对栈的指令操作, 均基于SS对当前栈的引用
- 通常由高地址向低地址扩展(PUSH时ESP自减,POP时ESP自增)
- CPU不自动自增%esp, 而是由每个指令序列最后的“ret”指令进行自增
PUSH:将字(或双字)压栈 (ESP先自减) POP:将字(或双字)弹出栈 (ESP后自增)
- ENTER:(函数开始时执行,用于建立新的栈帧)
- PUSH EBP【将当前栈帧的基址指针(EBP)压入栈中,这样做的目的是保存调用函数的栈帧基址,以便于在函数返回时恢复。】
- MOV EBP, ESP【栈指针(ESP)的值复制到 EBP 中,这样 EBP 就指向了新的栈帧的底部。此时,EBP 被用作当前栈帧的基址指针,所有的局部变量和参数都可以通过 EBP 加上相应的偏移量来访问。】
- LEAVE:(函数结束时执行)退出栈帧, 等价于:
- MOV ESP, EBP【将EBP的值复制回ESP,这样ESP就指向了调用函数的栈帧的底部,即返回地址的上方。】
- POP EBP
EBP:(StackSeg段中的)栈内数据指针, 栈帧的基地址, 用于为函数调用创建栈帧【用来恢复的】 ESP:(StackSeg段中的)栈指针, 栈区域的栈顶地址 EIP: 存放当前代码段中将被执行的下一条指令的线性地址偏移
栈帧: 是将调用函数和被调用函数联系起来的机制, 栈被分割为栈帧。栈帧的内容包含:
- 函数的局部变量
- 向被调用函数传递的参数
- 函数调用的联系信息(栈帧相关的指针: 栈帧基址针,返回指令指针)
返回指令指针: 由CALL指令压入栈中的EIP寄存器中的指令地址 该地址是被调用函数返回后首先执行的调用函数指令的地址, 即调用函数中 CALL指令的下一条指令的地址
CALL指令语义
- 将EIP的当前值(返回指令指针)压栈
- 将CALL的目标指令(被调用函数的第一条指令)的地址偏移
- 载入EIP寄存器
RET:返回指令,操作为将栈顶数据弹出至 eip。
RET N指令执行之前
- EBP -> ESP: 清空当前被调用函数的栈帧(此时ESP指向的栈顶内容恰好为调用者函数的EBP)(可选)
- POP EBP: 将EBP恢复为调用者函数的原始EBP 将栈顶的内容(返回指令指针)弹出到EIP 若RET N指令有参数n, 则将ESP增加n字节, 从而释放栈上的参数 恢复对调用函数的执行
调用惯例(Calling Convention)
调用惯例是对函数调用时如何传递参数和返回值的约定
- 参数传递用寄存器?用栈?两者都用?
- 参数从左到右/从右到左压栈?
- 返回值存储在栈?寄存器?两者都存?
x86主要调用惯例:
- cdecl: C语言中使用(GCC, GNU libraries); 参数从右到左压栈;EAX, ECX, EDX不保存(调用者应自己保存); 返回值由EAX返回;调用者清理栈 (ESP自增)
- stdcall: 常用于Win32 API, 被调用者清理栈(RETN n)
- fastcall: 类似于stdcall, 但使用寄存器ECX、EDX传递函数 的前2个参数
2.9 ELF(Executable and Linkable Format) - LINUX下文件格式
- ELF:ELF格式的文件常简称对象文件, 对象文件参与程序的链接和执行
- 编译过程:
- 高级语言–(编译器)–>汇编语言–(汇编器)–>二进制目标代码–(连接器)–>可执行程序
- 汇编代码: 由汇编指令组成, 体系结构相关(x86, x64, ARM,SPARC等)
- 目标码: 由汇编指令的逐字节的编码组成
- 链接器: 将来自不同编译单元(文件、库)的目标码链接为一个可执行程序
- 可执行程序: 又称为机器码(machine code), 以特定文件格式存在(如ELF或PE)
- 编译过程例子:
- 源码
1 2 3 4 5
#include <stdio.h> int main() { printf("Hello, World!"); return 0; }
- 编译结果(hello.s)
执行“gcc -S -o hello.s hello.c” (-S选项: 仅编译, 不汇编, 不链接)
.file "hello.c" .text .section .rodata .LC0: .string "hello world!" .text .globl main .type main, @function main: .LFB0: .cfi_startproc pushq %rbp .cfi_def_cfa_offset 16 .cfi_offset 6, -16 movq %rsp, %rbp .cfi_def_cfa_register 6 subq $16, %rsp movl %edi, -4(%rbp) movq %rsi, -16(%rbp) leaq .LC0(%rip), %rdi call puts@PLT movl $0, %eax leave .cfi_def_cfa 7, 8 ret .cfi_endproc .LFE0: .size main, .-main .ident "GCC: (Ubuntu 7.5.0-3ubuntu1~18.04) 7.5.0" .section .note.GNU-stack,"",@progbits- 汇编结果(hello.o) 执行“gcc -c -o hello.o hello.s”(-c选项: 编译且汇编, 但不链接)
- 两种链接方式
- (动态)链接为可执行程序
- 执行“gcc -o hello hello.o”, 输出为可执行程序hello
- 以汇编生成的hello.o、系统库的目标文件、libc库文件等作为链接输入, 生成可以在特定平台运行的可执行程序
- 默认情况下为动态链接: 生成的可执行程序体积小, 执行时需装载所需的动态库
- 纯静态链接(禁止与共享库链接)
- 执行“gcc -static -o hello_static hello.o”, 输出为可执行程序hello_static
- 生成的可执行程序包含程序运行所需的全部库, 但程序体积较大
- (动态)链接为可执行程序
- 源码
- 文件分层:
3.软件漏洞利用与防护
这部分是考试中最重要的,学长的文章讲的蛮好的
内存破坏漏洞: 栈溢出, 整数溢出, 堆溢出, Use after free, Double free, Type Confusion, 格式化字符串, 防御性编程
高级防御与攻击: stack canaries, 数据执行保护DEP, 代码注入, 代码重用, return-to-libc, ASLR, 面向返回的编程ROP
3.1 攻击手段1 —— 栈溢出^
3.2 攻击手段2 —— 整数溢出
整数溢出(Integer Overflow)是指一个整数值增大到超过其允许的最大值或减小到超过其允许的最小值的现象。整数溢出主要有两种类型:有符号溢出和无符号溢出。
3.2.1 有符号溢出
有符号整数溢出发生在整数值超过其最大值或最小值后溢出到符号位。例如:
signed int类型的最大值是2,147,483,647,最小值是-2,147,483,648。- 如果
si = INT_MAX,即si = 2,147,483,647,当si++后,si的值变为-2,147,483,648。
3.2.2 无符号溢出
无符号整数溢出指一个无符号整数值超过其表示范围后循环回零。例如:
unsigned int类型的最大值是4,294,967,295。- 如果
ui = UINT_MAX,即ui = 4,294,967,295,当ui++后,ui的值变为0。
实例代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
unsigned int ui;
ui = UINT_MAX; // 4,294,967,295
ui++;
printf("ui = %u\n", ui); // ui == 0
ui = 0;
ui--;
printf("ui = %u\n", ui); // ui == 4,294,967,295
signed int si;
si = INT_MAX; // 2,147,483,647
si++;
printf("si = %d\n", si); // si == -2,147,483,648
si = INT_MIN; // -2,147,483,648
si--;
printf("si = %d\n", si); // si == 2,147,483,647
3.2.3 整数溢出漏洞示例
- JPEG处理中的整数溢出:
在处理JPEG文件的comment域时,长度值len的减法操作可能导致整数溢出,进而导致内存分配错误和潜在的缓冲区溢出。
1 2 3 4 5 6 7
void getComment(unsigned int len, char *src) { unsigned int size; size = len - 2; // 如果len为1,size会被解释为一个大正值0xffffffff char *comment = (char *)malloc(size + 1); // size + 1 是0 memcpy(comment, src, size); return; }
- 负索引漏洞:
当有符号数在作为数组索引之前被转换为无符号数时,可能会导致数组访问越界。
1 2 3 4 5 6 7 8
char buf[N]; int len; read(fd, &len, sizeof(len)); if (len > N) { error("invalid length"); return; } read(fd, buf, len); // len 被转换为无符号数,负的len值会导致溢出
- 截断错误:
当一个长整型变量被截断成短整型变量时,可能会导致溢出。
1 2 3 4 5 6 7 8 9 10 11
int func(char *name, long cbBuf) { unsigned short bufSize = cbBuf; char *buf = (char *)malloc(bufSize); if (buf) { memcpy(buf, name, cbBuf); ... free(buf); return 0; } return 1; }
3.3 攻击手段3 —— 堆溢出
堆溢出(Heap Overflow)是指在堆上动态分配的内存空间发生缓冲区溢出的现象。堆溢出主要利用程序在堆上分配内存时的错误,往往会导致数据覆盖、程序崩溃甚至执行任意代码。
3.3.1 堆溢出的基本概念
堆溢出发生在动态分配内存的过程中,例如通过malloc、calloc、realloc等函数。攻击者可以通过输入超出预期大小的数据来覆盖堆中的关键数据结构或控制数据,从而达到执行任意代码的目的。
3.3.2 堆溢出示例
以下是一个简单的堆溢出示例代码:
1
2
3
4
5
6
7
8
9
10
int authenticated = 0;
char *packet = (char *)malloc(1000);
while (!authenticated) {
PacketRead(packet);
if (Authenticate(packet))
authenticated = 1;
}
if (authenticated) {
// 执行敏感操作
}
在这个示例中,PacketRead函数将数据读入packet缓冲区。如果PacketRead函数没有对输入数据的长度进行适当的检查,攻击者可以通过输入超过1000字节的数据来覆盖堆中的其他数据,包括authenticated变量,进而绕过身份验证。
3.3.3 防御措施
针对整数溢出和堆溢出,常见的防御措施包括:
- 输入验证:严格检查所有输入的数据长度和范围,防止超出预期范围的数据导致溢出。
- 安全函数:使用安全的库函数,如
strncpy、snprintf等替代不安全的函数。 - 内存保护:启用堆保护机制,如
Canary、ASLR(地址空间布局随机化)等。 - 代码审计:定期进行代码审计,发现并修复潜在的漏洞。
3.4 防护手段1 —— stack canaries^
3.4.1 stack canaries基本概念
- stack canaries是栈溢出的检测机制,又称“栈cookies”
- 由gcc的StackGuard实现
- 原理:将一个dummy值(或随机值)写到栈上的返回地址之前,并在函数返回时检查该值。不小心构造的栈溢出(假定是顺序栈粉碎)会覆写该“canary”单元,该行为将被探测到。
- 攻破StackGuard的基本方法:
- 如果canary所使用的随机值范围很小,则枚举每种可能性。
- 或先实施一个memory disclosure攻击,获知canary的值。StackGuard无法抵御disclosure攻击 —— 对缓冲区的“overread”,攻击者读取超出栈缓冲区之外的值,从而获取canary的值。对SSL的Heartbleed攻击就是一个disclosure攻击例子:

- 有时不需要覆写返回地址(缓冲区溢出),可以溢出:
- 劫持函数指针:如果攻击者能够修改函数指针(比如通过溢出覆盖局部变量),他们可以改变程序的控制流,使程序调用攻击者指定的函数。这通常涉及到覆盖函数指针,使其指向恶意代码。
- 安全敏感的局部变量:如果局部变量是安全敏感的,比如用于控制程序流程的变量,攻击者可以通过溢出来修改这些变量的值。
- 堆数据:如果攻击者能够通过溢出来访问或修改堆上的数据,他们可能会破坏程序的内存管理,导致未定义行为或执行恶意代码。
- 全局数据:全局变量通常在整个程序的生命周期内都存在,如果攻击者能够修改这些变量,他们可能会破坏程序的状态或行为。
3.4.2 stack canaries攻击的例子
1
2
3
4
5
6
7
8
void foo () {...}
void bar () {...}
int main() {
char buf [16];
void (*f) () = &foo;
gets(buf);
f();
}
其中包含了两个函数foo和bar,以及一个main函数。程序中定义了一个16字节大小的字符数组buf和一个函数指针f,该指针初始指向foo函数。然后使用gets函数读取用户输入到buf,接着调用f指针指向的函数。由于gets函数不检查缓冲区边界,如果用户输入超过16字节,将会导致缓冲区溢出。
在这个场景中,如果攻击者不能直接溢出返回地址,可溢出缓冲区, 使得函数指针被修改为bar的地址, 然后函数调用将调用bar而非foo:
-
溢出缓冲区修改函数指针:如果
f指针位于buf附近,攻击者可以构造一个足够长的输入,使得溢出的数据覆盖f指针,将其指向bar函数的地址。这样,当执行f()时,实际上会调用bar函数。 -
使用堆溢出劫持函数指针:如果函数指针存储在堆上,攻击者可以通过溢出堆上的其他数据结构来覆盖函数指针,使其指向攻击者选择的函数。
-
劫持全局函数指针:如果程序中使用了全局函数指针,攻击者可以通过溢出程序中其他可写的全局变量来修改这些指针。
-
劫持全局偏移量表(GOT)中的函数指针:在支持动态链接的程序中,全局偏移量表(GOT)用于存储动态链接库中函数的地址。如果攻击者能够溢出GOT中的条目,他们可以改变动态链接函数的地址,使得调用这些函数时实际执行的是攻击者指定的代码。
为了防止这类攻击,开发者应该采取以下措施:
- 使用更安全的输入函数,如
fgets代替gets。 - 对所有缓冲区操作进行边界检查。
- 使用编译器的安全特性,如堆栈保护和非执行栈。
- 对于动态链接库,使用地址空间布局随机化(ASLR)和堆栈保护等安全机制。
- 避免使用全局或可写的函数指针,或者确保它们不会被溢出的数据覆盖。
/* global static data - targeted for attack */
struct chunk {
char inp[64]; /* input buffer */
void (*process)(char *); /* ptr to function */
} chunk;
void showlen(char *buf)
{
int len;
len = strlen(buf);
printf("buffer6 read %d chars\n", len);
}
int main(int argc, char *argv[])
{
setbuf(stdin, NULL);
chunk.process = showlen;
printf("Enter value: ");
gets(chunk.inp);
chunk.process(chunk.inp);
printf("buffer6 done");
}
- 溢出缓冲区:攻击者输入构造的载荷,当gets(chunk.inp)被调用时,输入的数据将溢出inp缓冲区,并覆盖紧随其后的process函数指针。
- 覆盖函数指针:溢出的数据中的新函数指针地址将覆盖原始的process指针,指向攻击者指定的函数。
- 触发恶意函数调用:当程序执行chunk.process(chunk.inp)时,由于process指针已被覆盖,程序将调用攻击者指定的恶意函数。
3.4.3 针对攻击的防御手段
让函数指针位于其他类型数据的下方(更低地址)
在全局数据区和其他管理表结构之间使用守卫页(Guard Pages):
- 也是一种运行时检测方法, 可以看作StackGuard的扩展
- 在一个进程地址空间中关键内存区域之间放置守卫页(像一些gaps)
- 需借助CPU内存管理单元(MMU)的管理功能将它们标记为非法地址
- 任何对其的访问尝试都导致进程被终止
- 效果: 能失效缓冲区溢出攻击, 特别是对全局数据区的溢出攻击
- 甚至可以在栈帧之间、或者堆缓冲区之间放置守卫页
- 可以提供更进一步的保护, 防止栈溢出和堆溢出攻击
- 会导致执行时间和内存的很大开销, 因为要支持大量页映射
3.5 防护手段2 —— 数据执行保护DEP^:Data Execution Prevention
tips:
DEP【Win中】又称作Nx-bit【Linux中】(non executable bit),W⊕X
DEP 能够阻止代码注入攻击。
冯诺依曼体系结构将代码作为数据存储,使得攻击者可以向栈或堆注入代码, 而栈和堆原本只应该存储数据。
很多缓冲区溢出攻击涉及将机器码复制到目标缓冲区, 然后将执行转移到这些缓冲区。
一种防御方法就是阻止在栈/堆/全局数据区中执行代码, 并假定可执行代码只能出现在进程地址空间中除这些位置外的其他位置需要CPU内存管理单元(MMU)提供支持, 将虚拟内存的对应页标记为不可执行。对于每一个被映射的虚拟内存页, 都有这样额外的1个no-executebit, 置位时, 表示该页的数据不能作为代码执行, 一旦程序控制流到达该页, CPU会产生陷入
DEP被绝大多数操作系统和指令集体系结构支持
DEP将栈和堆置为不可执行, 对多种缓冲区溢出攻击提供了一种 高度的保护。但有一些合法程序需要将可执行代码放在栈上:如Java运行时系统、运行时代码生成、Linux信号处理程序等。
3.6 攻击DEP —— 代码重用^
3.6.1 return-to-libc
它利用了C语言标准库(libc)中的函数来执行攻击者的命令。在这种攻击中,攻击者不直接注入Shellcode,而是通过溢出或其他方式覆盖函数的返回地址,使其指向libc库中的某个函数地址。然后,攻击者通过修改函数的参数来控制函数的行为,实现攻击目的。
在内存中确定某个函数的地址,并用其覆盖掉返回地址。由于 libc 动态链接库中的函数被广泛使用,所以有很大概率可以在内存中找到该动态库。同时由于该库包含了一些系统级的函数(例如 system() 等),所以通常使用这些系统级函数来获得当前进程的控制权。鉴于要执行的函数可能需要参数,比如调用 system() 函数打开 shell 的完整形式为 system(“/bin/sh”),所以溢出数据也要包括必要的参数。下面就以执行 system(“/bin/sh”) 为例,先写出溢出数据的组成,再确定对应的各部分填充进去。
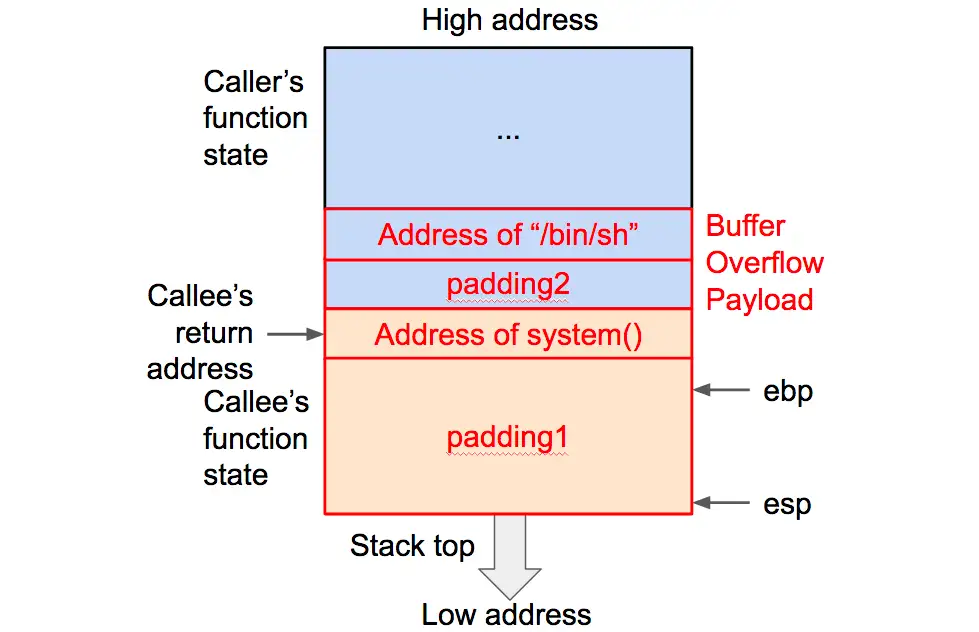
3.6.2 代码注入和代码重用的关系与区别
3.7 攻击手段4 —— 面向返回的编程ROP^
3.7.1 ROP^
修改返回地址,让其指向内存中已有的一段指令 —— 执行任意行为, 不需要注入代码。利用的是任意充分大的程序代码基。
指令指针(%eip)决定哪一条指令被获取和执行 一旦CPU执行了指令, 就会自动改变%eip的值到下一条指令。 控制流随着%eip的更改而演进
栈顶指针%esp决定哪个指令序列被获取和执行(作为程序计数器PC) CPU不自动自增%esp, 而是由每个指令序列最后的“ret”指令进行自增
想要完成ROP,要完成的任务包括:在内存中确定某段指令的地址,并用其覆盖返回地址。可是既然可以覆盖返回地址并定位到内存地址,为什么不直接用上篇提到的 return2libc 呢?因为有时目标函数在内存内无法找到,有时目标操作并没有特定的函数可以完美适配。这时就需要在内存中寻找多个指令片段,拼凑出一系列操作来达成目的。假如要执行某段指令(我们将其称为“gadget”,意为小工具),溢出数据应该以下面的方式构造:
(param for gadget 1)
payload : padding + address of gadget 1 + param for gadget 1 + address of gadget 2 + param for gadget 2 + …… + address of gadget n + shellcode
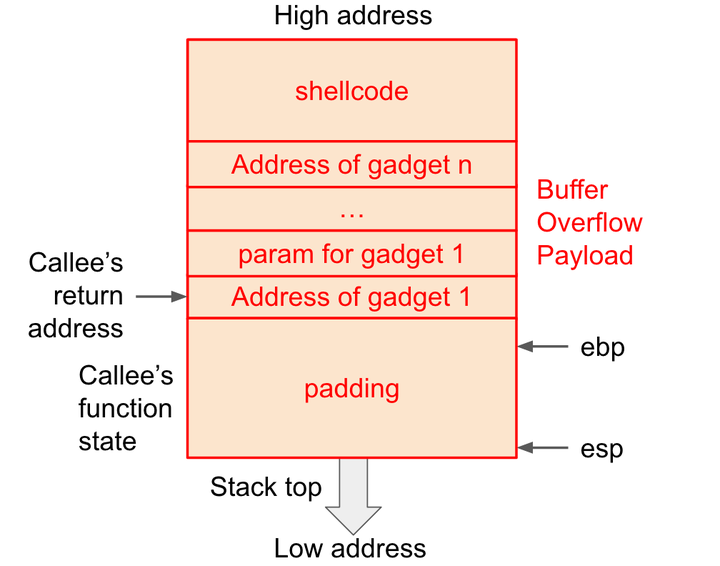
3.7.2 ASLR^
- 对于位置无关的可执行程序(PIE), 随机化该可执行程序的基地址
- 所有库都是PIE, 因此它们的基地址被随机化
- 主可执行程序可能不是PIE, 故可能无法被ASLR保护
- 关注的是内存块的随机化
- ASLR是一种粗粒度的随机化形式
- 只有基地址被随机化
- 在内存对象之间的相对距离不变
- ATTACK-ASLR
- 如果随机地址空间很小, 可以进行一个穷举搜索
- 例如, Linux提供16位的随机化强度, 可以在约200秒以内被 穷举搜索攻破
- ASLR经常被memory disclosure攻破
- 例如, 如果攻击者可以读取指向栈的指针值, 他就可以使用该指针值发现栈在哪里
- 如果随机地址空间很小, 可以进行一个穷举搜索
3.8 攻击手段5 —— 格式化字符串
格式化字符串攻击(Format String Attack)是一种利用程序中对格式化字符串处理不当的漏洞进行的攻击。以下是这一部分的详细知识点总结:
基本原理
- 概念:格式化字符串攻击利用了函数(如
printf)在处理用户输入的字符串格式时的漏洞,通过特制的输入字符串,攻击者可以执行未预期的操作。 - 示例代码:
1 2 3
int main(int argc, char *argv[]) { if (argc > 0) printf(argv[1]); }
- 当用户输入
hello%d%d%d%d%d%d时,程序会输出传参寄存器和栈上的内容。 - 如果输入
hello%s%s%s%s%s%s%s%s%s,printf会使用传参寄存器和栈上的后续多个值作为字符串地址,可能导致段错误。
- 当用户输入
常见攻击方法
- 查看/修改内存:
- 使用
%x、%s等格式化符号可以查看内存内容。 - 使用
%n可以向指定地址写入数据。
- 使用
- 代码注入:
- 通过构造特定的输入,直接将恶意代码放入字符串中执行。
攻击示例
- 查看寄存器和内存:
1 2 3
int i; printf("foobar%n\n", (int *)&i); printf("i = %d\n", i);
- 以上代码将输出
i = 6,因为%n会将当前输出字符数写入参数指向的地址。
- 以上代码将输出
- 任意地址写入:
- 输入
foobar%10u%n可能向内存位置写入16。
- 输入
防御措施
- 硬编码字符串:避免用户输入作为格式化字符串。
- 避免使用
%n:尽量不要使用能够修改内存内容的格式化符号。 - 使用安全的字符串处理函数:如
snprintf等限制输入长度的函数。 - 编译器检查:利用编译器的格式化字符串检查功能。
- 验证输入:严格验证用户输入,防止间接的格式化字符串攻击。
修复方法
- 修改
printf用法:1
printf("%s", argv[1]);
- 防止缓冲区溢出:
- 使用
%.400s而不是%400s,以限制字符串长度。
- 使用
格式化字符串攻击因其灵活性和破坏力,成为了安全漏洞中需要重点防范的一种类型。通过严格的输入验证和安全编码实践,可以有效减少此类攻击的风险 。
3.9 防御性编程(p91页开始到结束)
防御可以在不同的时机进行:
- 编程前
- 开发过程中(防御性编程)
- 测试时(fuzzing, . . .)
- 代码运行时(检测和缓解: stack canaries, DEP, . . .)
3.9.1 使用更安全的编程语言
C, C++, Objective-C不安全
安全语言出现了(早期Algol->Ada/java->Go、Rust),自动检查避免了程序员显式实现检查逻辑,但内建安全必然伴随着运行时开销。且即便是对于更安全的语言——它们的实现仍然使用的是C/C++且它们的库可能用C/C++实现;它们可能允许与不安全的代码通过外部函数接口(Foreign FunctionInterface,FFI)交互,如:Java的JNI接口。
3.9.2 进行代码评审
- 费根检查:逐句审阅代码,使用已知错误的检查表(checklist)
- 错误的数据使用: 变量未初始化, 悬空指针, 数据索引越界
- 声明错误: 未声明的变量, 变量声明了两次
- 计算错误: 除零, 混合类型表达式, 错误的操作符优先级
- 关系表达式错误: 错误的布尔操作, 错误的操作符优先级
- 控制流错误: 无限循环, 循环执行n-1或n+1次而非n次
3.9.3 编译时防御:使用编译器的机制
-
GCC编译器内建的-D_FORTIFY_SOURCE=2选项。将一些字符串/内存操作函数调用替换为有边界检查的版本,并插入边界:文档列表: memcpy(3), mempcpy(3), memmove(3), memset(3),stpcpy(3), strcpy(3), strncpy(3), strcat(3), strncat(3),sprintf(3), snprintf(3), vsprintf(3), vsnprintf(3), gets(3)
-
Ubuntu和Fedora系统默认使用‐D_FORTIFY_SOURCE=2和-fstackprotector
3.9.4 编写内存安全的代码
边界检查(bounds checking): 对于超出边界的访问,可以:
- 停止程序
- 忽略访问, 可能导致截断的数据(truncated data)
对于目标缓冲区/字符串, 自动调整大小。如果有需要, 移动目标缓冲区/字符串
手段:
- 使用边界检查库函数
- 使用更安全的库
- 在C/C++程序中, 使用C库函数编程时, 易出现以下内存风险:
- 缓冲区溢出(Buffer overflows)
- NULL终止错误(null-termination errors)
- 差一错误(off-by-one errors)
- 在C/C++程序中, 使用C库函数编程时, 易出现以下内存风险:
3.9.5 输入验证(p118)
tips:
3.9.6 防御性编程总结
- 好的实践
- 使用更安全的编程语言
- 进行代码评审
- 使用编译器的机制, 包括StackGuard(下一节)
- 编写内存安全的代码
- 使用边界检查库函数,使用更安全的库
- 输入验证
- 识别攻击面: 程序从信道获得输入
- 最小化攻击面
- 将所有输入都看作潜在恶意的
4.模糊测试
软件测试基础(指标定义), 模糊测试原理、分类及指标, AFL简介, 渗透测试概述
4.1 软件测试基础
- 程序测试:测试用例集合上运行程序, 并比较实际结果与预期 结果的过程,测试不能保证程序的正确性,能够找到很多bug
- 如何设计测试集
- 黑盒测试
- 主要关注软件的功能性能,而不是代码的结构
- 仅关注软件的输入和输出,以验证软件的功能是否符合要求规范
- 白盒测试
- 对应用程序的代码和内部结构有深入了解
1 2 3 4
static int maxOfThree (int x, int y, int z) { if (x>y) if (x>z) return x; else return z; else if (y>z) return y; else return z; }
一个合理的测试策略是覆盖以下4种情况 x > y ∧ x > z x > y ∧ x ≤ z x ≤ y ∧ y > z x ≤ y ∧ y ≤ z
- 对应用程序的代码和内部结构有深入了解
- 灰盒测试
- 黑盒测试
- 测试覆盖率
- 核心思想:没有被测试覆盖的代码更有可能存在bug
- 将程序切分成不同元素(element)
- 测试集的覆盖率定义为:$\frac{被测试集执行的元素的个数}{程序中元素的总个数}$
- 100%->终止
- 指标
- 点/边覆盖率
- 例子
- 代码:
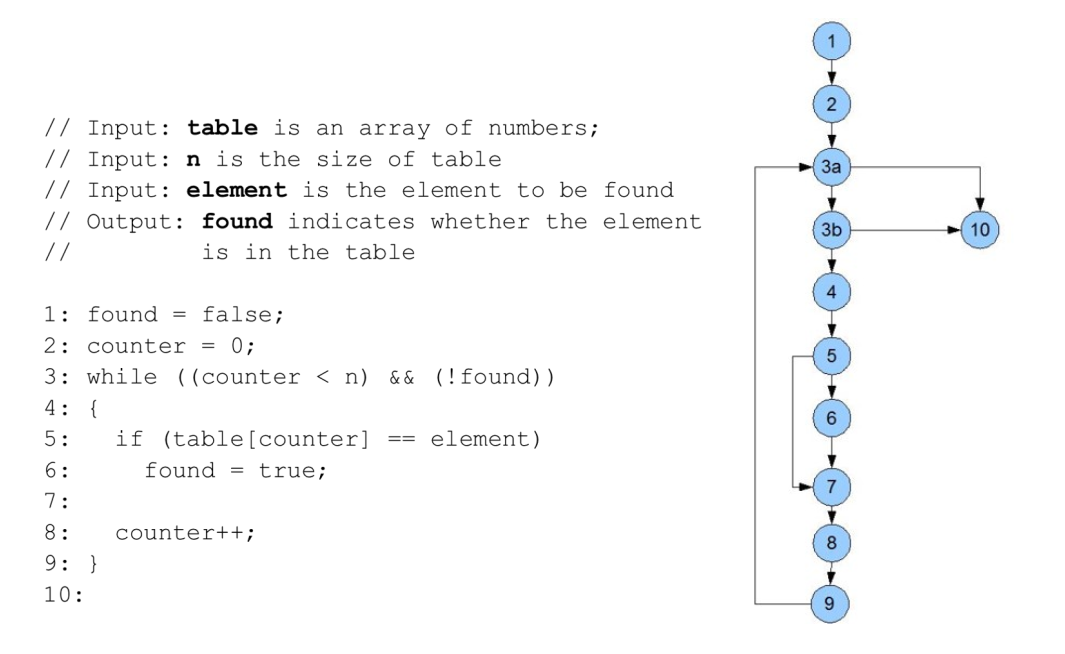
- 测试例
- 0次循环迭代: table={ }; n=0; element=3
- 1次循环迭代: table={3,4,5}; n=3; element=3
- 2次循环迭代: table={3,4,5}; n=2; element=4
- 代码:

4.2 模糊测试

4.2.1 前期预处理
在开始模糊测试流程之前,许多模糊测试工具需要执行一系列预处理步骤。这些步骤主要涉及对目标程序的插桩,目的是去除潜在的冗余配置,优化种子集,并创建能有效触发应用程序的测试样例。此外,预处理阶段还包括为接下来的输入生成(即输入生成阶段)做好准备,建立必要的模型。
- 插桩
- 插桩是指在目标程序的源代码或二进制代码中插入特定的代码段,以便在程序运行时收集执行信息。通过插桩,可以监控程序的执行路径,记录哪些代码块被执行了,哪些没有被执行,从而帮助识别潜在的漏洞和薄弱点。
- 可以分为静态和动态两种类型。
- 静态插桩在程序运行前的预处理阶段进行,通常作用于源代码或中间代码,并在编译时完成。这种方式的优势在于,因为处理是在运行前完成的,所以运行时的开销相对较低。如果程序依赖库文件,这些库也需进行插桩,通常是通过使用相同技术重新编译实现的。除了源代码,也有针对二进制代码的静态插桩工具。
- 动态插桩虽然运行时开销更大,但它可以在程序运行时方便地对动态链接库进行插桩。当前,有多种著名的动态插桩工具,如DynInst、DynamoRIO、Pin、Valgrind和QEMU。模糊测试工具可能支持一种或多种插桩技术。比如,AFL既可以在源代码级别通过修改编译器实现静态插桩,也可以利用QEMU在二进制级别进行动态插桩。在采用动态插桩时,AFL提供两种选项:一是默认情况下只对目标程序的可执行代码进行插桩;二是通过启用AFL_INST_LIBS选项,对目标程序及其所有外部库代码进行插桩。虽然后者能增加代码的覆盖范围,但也可能扩大AFL对外部库函数的测试范围。
-
种子选择
种子是指初始输入的集合,作为模糊测试的起点。选择高质量的种子集非常重要,因为它们直接影响测试的覆盖率和效果。一个好的种子集应尽可能涵盖目标程序的不同功能和路径,以便充分测试程序的各种行为。在基于变异的模糊测试中,所使用的种子文件有广泛的选择范围。例如,在对一个接收MP3文件的MP3播放器进行模糊测试时,从无限的有效MP3文件中选择合适的种子文件变成了一个挑战,这就是所谓的种子选择问题。 -
种子裁剪
种子裁剪是指在初始种子集中去除冗余的或无效的输入,以优化种子集的质量。通过种子裁剪,可以减少测试时间,提高测试效率,并确保每个种子都有其特定的测试价值。【AFL通过迭代使用与代码覆盖率相关的工具来修剪种子,确保修剪后的种子保持了相同的覆盖范围。】 - 驱动程序
驱动程序是用于自动化测试过程的工具或脚本,它负责将种子输入提供给目标程序,并收集程序的输出和执行信息。一个高效的驱动程序应能够处理各种类型的输入,并在测试过程中准确记录程序的行为和结果。
4.2.2 调度算法选择
模糊测试中的调度算法用于决定在测试过程中如何选择和分配测试用例。不同的调度算法可以显著影响测试效率和覆盖率。
4.2.3 测试用例生成策略
测试用例生成策略决定了如何从现有的种子集生成新的测试用例。常见的生成策略包括变异(mutations)和重组(recombinations)等。这些策略的选择和组合将影响模糊测试的全面性和有效性。
5.软件自我保护
MATE攻击模型, 代码混淆, 软件防篡改, 软件水印, 软件胎记
5.1 MATE(Man-At-The-End)攻击模型
- 攻击者: 位于终端,对终端计算资源有高控制权限
- 攻击对象:安装在受控终端上的软件程序
- 攻击(表象)目的: 获悉、篡改软件的内部逻辑
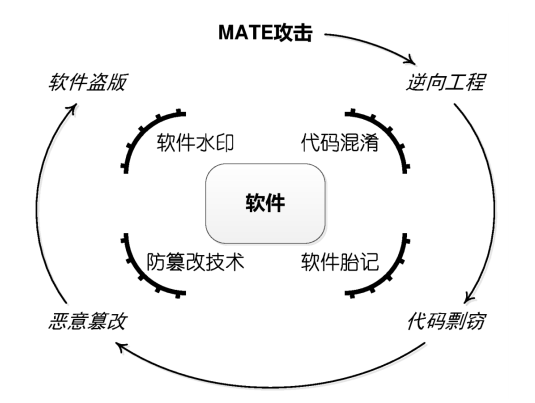
5.2 代码混淆Obfuscation
-
目标:阻止对软件实施非授权的逆向分析【用于保护软件的知识产权和防止恶意分析】
-
核心方法:语义保留的程序变换。【通过重构增加代码逆向分析难度的技术】
- 完美混淆器:借鉴密码学算法的安全模型
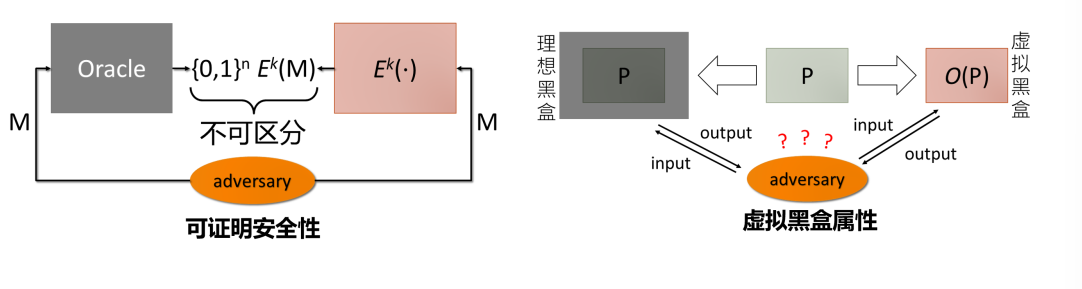
- 虚拟黑盒:指的是攻击者无法通过观察程序的行为来推断出程序的内部逻辑或结构。即使攻击者可以观察到程序的输出,他们也无法比拥有程序的oracle(即可以直接查询程序输出的接口)的攻击者获得更多的信息。
- 类似于“选择明文攻击”:攻击者可以向程序提交任意输入,并在多项式时间内获得相应的输出,但无法看到程序的内部工作机制。
- 满足虚拟黑盒属性的完美混淆器不存在。现实中, 不需要提供理论上不可分析的绝对严格保护,仅需使逆向分析开销大于可能受益。
- 代码混淆的实际能力
- 做不到:让程序的执行逻辑变得不可知
- 做得到:使程序的执行逻辑变得难以理解
-
数据混淆
- 控制流混淆
6.Web安全
SQL注入(要求我们抽象一下PPT例子中的表达,例如给出注入的分类), XSS, CSRF
6.1 SQL注入^
SQL语言的核心结构:
- Sth. to do
- @ target
- Sth. to do (optional)
- under condition (optional)
6.1.1 一些例子-1:
输入username:’; drop TABLE Accounts;/*
SELECT * FROM Accounts WHERE Username = ’ ’
SELECT * FROM Accounts WHERE Username = ’’; drop TABLES Accounts; /*’AND Password = ’geheim’;
6.1.2 一些例子-2:
输入Username:’OR 1=1;/*
SELECT * FROM Accounts WHERE Username = ’’ AND Password = ’’;
SELECT * FROM Accounts WHERE Username = ’’ OR 1=1;(被终结在这) /*’AND Password = ’geheim’;(这里注释掉了)
※ 6.1.3 SQL注入原理:
SQL语言中的一些特殊符号
- ;:意味着指令结束,有可能开始下一个指令
- ’:用于字符串常量,系统在输入命令中顺序匹配
- # 或 –:意味着注释,出现在其后的内容会被系统忽略掉
- /* … */:用于多行注释,可以跨多行。
上述符号使得经过设计的SQL语句可以篡改设计者事先定义的查询语义
6.1.4 数字型漏洞
http://xxx.xxx.xxx/abcd.php?id=XX 若XX为数字类型,例如页码、 ID等,存在注入时则为数字类型的注入
①给参数赋值为or 1=1,页面正常 http://xxx.xxx.xxx/abcd.php?id=XX or 1=1
②接着给参数赋值为and 1=2,页面报错 http://xxx.xxx.xxx/abcd.php?id=XX and 1=2
1
2
select * from <表名> where id=XX or 1=1
select * from <表名> where id=XX and 1=2
6.1.5 字符型漏洞
http://xxx.xxx.xxx/abcd.php?id=XX 若XX为字符串,注入测试需使用单引号来闭合
①给参数赋值为or 1=1,页面正常 http://xxx.xxx.xxx/abcd.php?id=XX ’or ‘1’=‘1
②接着给参数赋值为and 1=2,页面报错 http://xxx.xxx.xxx/abcd.php?id=XX ’and ‘1’=‘2
select * from <表名> where id=‘XX’ or ‘1’=‘1’ select * from <表名> where id=‘XX’ and ‘1’=‘2
6.1.6 Hack方法
SQL注入过程典型示例
- 寻找可能存在SQL注入漏洞的链接
- 测试该网站是否有SQL注入漏洞
- 猜管理员帐号表
- 猜测管理员表中的字段
- 猜测用户名和密码的长度
- 猜测用户名
- 猜测密码
6.1.7 一些题目
SQL注入是一种安全漏洞,攻击者可以通过在应用程序的输入字段中注入恶意SQL代码,来操纵后端数据库。这种攻击可以导致数据泄露、数据丢失、数据库被破坏等严重后果。SQL注入的关键在于利用了SQL语言的特殊符号和结构,比如分号、单引号、注释符号等,来改变原有查询语句的语义。
- SQL注入攻击可能利用哪些特殊符号?(多选)
- A. 分号(
;) - B. 单引号(
') - C. 注释符号(
#或--)
- A. 分号(
- 描述SQL注入攻击中,攻击者如何利用单引号来闭合SQL语句?
- 答案:攻击者通过在输入字段中插入单引号来闭合正常的SQL语句,然后添加恶意的SQL代码。例如,如果原始查询是
SELECT * FROM Accounts WHERE Username = '输入的用户名',攻击者可以输入'; DROP TABLE Accounts; --,这样单引号闭合了原始的查询,后面的分号开始一个新的SQL命令,注释符号使得余下的内容被忽略。
- 答案:攻击者通过在输入字段中插入单引号来闭合正常的SQL语句,然后添加恶意的SQL代码。例如,如果原始查询是
- 为什么说SQL注入攻击可以改变原有查询语句的语义?
- 答案:SQL注入攻击通过注入恶意的SQL代码,可以完全改变原有的查询逻辑。例如,原本的查询可能是检索特定用户名的账户信息,但攻击者通过注入如
OR '1'='1'的代码,可以使查询永远返回真(因为1=1总是为真),从而绕过身份验证或检索不应该被访问的数据。
- 答案:SQL注入攻击通过注入恶意的SQL代码,可以完全改变原有的查询逻辑。例如,原本的查询可能是检索特定用户名的账户信息,但攻击者通过注入如
- 描述SQL注入攻击中数字型漏洞和字符型漏洞的区别。
- 答案:数字型漏洞通常发生在输入参数预期为数字类型时,攻击者可以通过添加逻辑表达式(如
or 1=1)来绕过正常的逻辑判断。字符型漏洞则发生在输入参数预期为字符串时,攻击者需要使用单引号来闭合字符串,并可能添加额外的SQL代码。两者的主要区别在于输入参数的数据类型和闭合方式。
- 答案:数字型漏洞通常发生在输入参数预期为数字类型时,攻击者可以通过添加逻辑表达式(如
6.2 XSS - Cross Site Scripting
也称为HTML注入
6.3 CSRF - Cross Site Scripting Forgery
7.引用监控器
8.恶意代码的机理及其防护
木马、病毒、蠕虫概念及区别
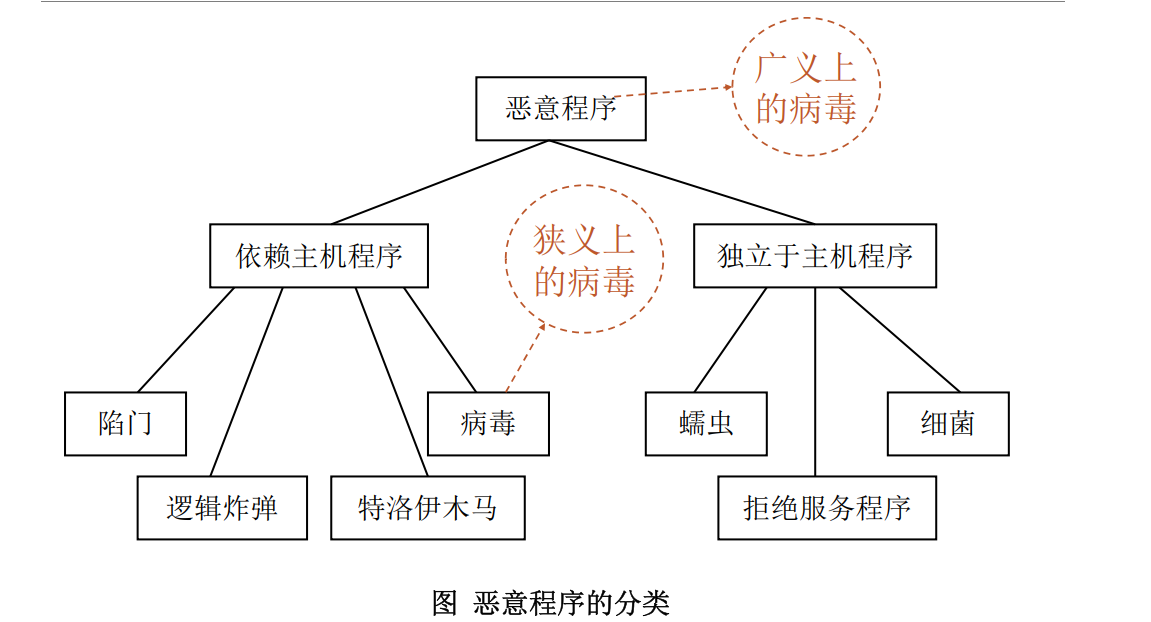
病毒的隐藏技术, 木马的隐藏技术
木马、病毒、蠕虫概念及区别
木马(Trojan):一种恶意软件,它隐藏在看似无害的软件或应用程序中,用户安装或运行这些程序时,木马会执行其恶意功能,如窃取数据、远程控制等。
病毒(Virus):一种自我复制的恶意软件,它可以感染其他文件或系统,并通过这些文件传播。病毒通常需要用户交互来传播,如打开受感染的附件。
蠕虫(Worm):一种自我复制的恶意软件,它可以独立于宿主文件运行,并通过网络或其他途径自动传播,不需要用户交互。
区别:
- 传播方式:木马通常需要用户交互,病毒和蠕虫可以自动传播。
- 依赖性:木马隐藏在其他软件中,病毒依赖于感染文件,蠕虫独立运行。
- 自我复制能力:病毒和蠕虫具有自我复制能力,而木马不具备。
- 木马、病毒和蠕虫都是什么类型的软件?
- A. 恶意软件
- B. 系统软件
- C. 应用软件
- D. 硬件
答案:A
- 下列哪些特点描述了木马?(多选)
- A. 隐藏在其他软件中
- B. 需要用户交互才能传播
- C. 可以自我复制
- D. 通常用于远程控制或数据窃取
答案:A, B, D
- 病毒和蠕虫的共同点是什么?
- A. 需要用户交互才能传播
- B. 可以自我复制
- C. 可以独立于宿主文件运行
- D. 通常通过电子邮件附件传播
答案:B
- 蠕虫与病毒的主要区别是什么?(多选)
- A. 蠕虫可以独立运行,病毒不能
- B. 病毒需要感染文件,蠕虫不需要
- C. 蠕虫通过电子邮件传播,病毒不通过电子邮件传播
- D. 病毒和蠕虫都可以通过网络传播
答案:A, B, D
病毒的隐藏技术
病毒和木马程序通常会使用各种隐藏技术来躲避检测和分析。以下是一些常见的隐藏技术:
反跟踪技术
- 反调试技术:通过检测调试器的存在来防止恶意软件被分析。方法包括检查调试标志、异常处理、时间检测等。
- 反虚拟化技术:检测虚拟机环境(如VMware、VirtualBox)以避免在虚拟环境中运行。
- 代码混淆:通过混淆代码结构,使逆向工程变得困难。
避开修改中断向量
- 隐藏中断处理程序:病毒避免直接修改中断向量表,而是通过更隐蔽的方法,如挂钩系统调用。
- 动态修改:仅在特定条件下修改中断向量,使得难以在静态分析中发现。
请求在内存中的合法身份
- 伪装合法进程:恶意软件伪装成系统进程或其他合法进程,以躲避检测。
- 进程注入:将恶意代码注入到合法进程中运行,从而利用合法进程的身份。
维持宿主程序的外部特性
- 文件隐形:修改文件属性或使用NTFS数据流(NTFS Alternate Data Streams)隐藏恶意代码。
- 感染技术:感染宿主程序时,保持宿主程序的大小和属性不变。
不使用明显的感染标志
- 无文件病毒:完全在内存中运行,不在磁盘上留下任何痕迹。
- 隐蔽通信:使用加密通信或伪装成正常网络流量,避免被检测到。
病毒的多态技术
多态技术使得病毒的每次感染产生的代码都不同,但功能相同,从而躲避静态分析和签名检测。多态技术包括以下几种方法:
多态技术中的密钥和解密代码变化多端
- 等价指令替换:用等价的指令替换解密代码中的指令。
- 寄存器替换:用不同的寄存器替换解密代码中的寄存器。
- 插入垃圾指令:在解密代码中插入无用的垃圾指令。
- 指令位置调换:在不影响功能的情况下,调换指令的前后位置。
多态引擎的组成
一个多态引擎通常包括以下模块:
- 指令位置变换模块:改变指令的顺序,以产生不同的代码结构。
- 寄存器变换模块:用不同的寄存器替换原有的寄存器。
- 指令扩展模块:用更复杂的指令序列替换简单指令。
- 指令收缩模块:用更简单的指令序列替换复杂指令。
- 等价指令替换模块:用等价的指令替换当前指令。
- 无用指令随机插入:随机插入无用的指令,使代码结构更加复杂。
- 垃圾指令插入:插入无用的垃圾指令,增加代码的混淆度。
木马的隐藏技术
木马程序(Trojan horse)使用多种技术隐藏自己,以避免被发现和删除。以下是一些常见的木马隐藏技术:
1. 文件和进程隐藏
- Rootkit:使用Rootkit技术隐藏木马的存在,Rootkit可以隐藏文件、进程、注册表项和网络连接。
- 进程注入:将木马代码注入到合法进程中运行,从而利用合法进程的身份。
- 文件隐形:修改文件属性或使用NTFS数据流(NTFS Alternate Data Streams)隐藏木马文件。
2. 反调试和反分析
- 反调试技术:通过检测调试器的存在来防止木马被分析,方法包括检查调试标志、异常处理、时间检测等。
- 反虚拟化技术:检测虚拟机环境(如VMware、VirtualBox)以避免在虚拟环境中运行。
- 代码混淆:通过混淆代码结构,使逆向工程变得困难。
- 自修改代码:在运行时动态修改自己的代码,使得静态分析变得困难。
3. 伪装和欺骗
- 伪装成合法软件:木马程序通常伪装成合法软件的安装包或更新程序,诱骗用户下载安装。
- 合法签名:利用被盗或伪造的数字签名,使木马程序看起来像是来自可信任的来源。
- 合法进程伪装:木马伪装成系统进程或其他常见进程,以躲避用户和安全软件的检测。
4. 持久化技术
- 注册表持久化:在Windows注册表的启动项中添加键值,使木马在系统启动时自动运行。
- 计划任务:创建计划任务,使木马定期运行或在特定条件下运行。
- 服务安装:将木马安装为系统服务,使其在后台持续运行。
5. 通信隐蔽
- 加密通信:使用加密协议(如HTTPS、TLS)与控制服务器通信,避免被网络监控工具检测到。
- 伪装成正常流量:将恶意通信流量伪装成正常的网络流量,例如HTTP流量、DNS查询等。
- 隐蔽信道:利用社交媒体、云存储服务等作为隐蔽信道传输数据。
6. 动态加载
- DLL注入:将恶意DLL文件注入到合法进程中,从而在合法进程的上下文中执行木马代码。
- 反射型DLL注入:不在磁盘上存储DLL,而是通过内存中的代码加载DLL,增加检测难度。
- 代码段劫持:劫持合法进程的代码段,将控制流引导到木马代码。
7. 持续更新和自我保护
- 自我保护:使用多种手段保护自身不被删除或终止,例如监控自身进程,防止被杀毒软件终止。
- 自动更新:定期从控制服务器获取最新版本,以躲避安全软件的签名检测和规则匹配。
- 多态和变种:使用多态技术不断变化自身代码,使得每次执行时代码不同,难以被特征匹配检测到。